4 шага для улучшения производительности сети
Сеть — это фундамент большинства предприятий, который поддерживает важные бизнес-приложения, предоставляя данные для принятия решений и позволяя общаться с клиентами, партнерами, поставщиками и сотрудниками. Сегодня сеть играет важнейшую стратегическую роль, и любой простой или снижение производительности сети или приложений напрямую влияют на работу организации. Для предоставления уровней обслуживания необходимо решить две задачи: использовать профилактические меры для оптимизации производительности и устранять любые проблемы как можно быстрее для сокращения времени простоя. Данная методология решения проблем с производительностью сети и приложений описывает подход, который поможет быстро выявлять первопричины всех проблем.
Введение
В современных корпоративных сетях становится все сложнее найти основную причину проблем с сетью и приложениями. Виртуализация распространяется из центра обработки данных на настольные компьютеры, набирают популярность облачные службы, а личные устройства на работе (BYOD) уже стали нормой. Проблемы могут возникнуть из-за растущего числа устройств Wi-Fi, чрезмерного использования полосы пропускания неавторизованными приложениями, ошибок конфигурации, плохой инфраструктуры доставки приложений и многих других причин. Увеличивающееся включение голоса и видео добавляет ещё больше сложностей и приводит к тому, что полоса пропускания подходит к своим пределам.
На исправление проблем с производительностью уходит все больше усилий и времени, так как специалисты пытаются решить, кто ими должен заняться.
Процесс устранения проблем с производительностью сети
Чтобы выяснить основную причину проблем с производительностью сети, используется процесс из четырех шагов.

Рисунок 1. Рабочий процесс устранения проблем.
Доступные инструменты для решения проблем делятся на две категории: системы управления сетью (NMS) и инструменты захвата и анализа пакетов.
NMS, в основном, используется на этапе мониторинга и оповещения, отслеживая работу маршрутизаторов и серверов компании. Однако некоторые NMS очень сложно правильно настроить, в результате чего они следят только за устройствами 3 уровня, а коммутаторы на 2 уровне остаются вне области мониторинга. Данные опроса устройств обобщаются за долгий период, что скрывает влияние пиков нагрузки. К тому же из-за того что система NMS расположена в центре, измерения, сделанные для анализа времени реакции конечных пользователей, оказываются неточными, потому что в тесте используются различные части сети для связи с оцениваемыми устройствами.
В процессе устранения неполадок полезность NMS уменьшается, так как она не предоставляет подробные сведения, необходимые для полного анализа проблем с производительностью.
Согласно данным опроса 3 000 сетевых специалистов, проведенного компанией NETSCOUT, 82 % респондентов считают низкую производительность сети и приложений критической проблемой, а 52 % считают, что возможностей NMS в большинстве случаев недостаточно для поиска причин снижения производительности. Кроме того, 51 % респондентов сообщили, что в большинстве случаев они вынуждены покидать свое рабочее место, чтобы устранить неполадку.
Чтобы получить более подробную информацию, сетевому инженеру необходимо использовать бесплатные или коммерческие инструменты захвата и анализа пакетов. Их роль на этапе оповещения ограничена, так как они рассматривают только одну точки в сети, но на стадии анализа причин они проявляют себя во всей красе. Для использования сложных инструментов анализа пакетов требуются квалифицированные опытные инженеры. При этом процесс отнимает много времени, а его результатом могут стать миллионы пакетов, которые нужно изучить в различных пользовательских интерфейсах. Все это делает процесс устранения неполадок гораздо более сложным и трудоемким.
Где проблемы прячутся в сети
Разрыв между инструментами — системы NMS без подробной информации о сети и сложными инструментами захвата пакетов — увеличивает среднее время устранения проблемы. Неявные, периодически проявляющиеся проблемы могут «прятаться» в сети, ухудшая производительность и репутацию ИТ-отдела.
Для быстрого анализа и устранения проблем с производительностью необходимо полное представление о всей сети: специализированное решение для автоматического анализа сетей и приложений, которое восполняет недостатки традиционных NMS и инструментов захвата пакетов.
Задачи, которые необходимо решить:
- Неуправляемое оборудование, которое приобрели из-за низкой цены, но при возникновении проблем диагностика обходится дороже, так как оно не дает сведений о состоянии каждого сегмента сети и уровнях использования. Например, при наличии управляемого коммутатора сетевой инженер может рассмотреть любой его порт, изучить ошибки, оценить загрузку порта и узнать, кто к нему подключен.
- Недокументированные сети — это вечная проблема, ведь сетевая конфигурация изменяется так часто, что любая документация быстро становится устаревшей. Физическая трассировка каналов займет много времени, но без точной документации инженер просто не будет знать, какие пакеты и куда поступают. Сетевым специалистам необходимы средства обнаружения реального времени во всей сети.
- Данных слишком много, хотя проблема может заключаться всего в нескольких пакетах. Диагностика будет проходить гораздо быстрее при использовании автоматизированного метода просеивания захваченных пакетов для поиска проблемы, а именно ориентированного на подход анализа «сверху вниз».
- Проблемы, возникшие в прошлом, которые попадаются инженеру на глаза после того, как они произошли. Необходимы средства для захвата и анализа больших объемов данных за длительные периода времени, скажем, за 24 часа, чтобы обнаруживать кратковременные проблемы.
- Новая технология, которая еще не контролируется, например Ethernet 10 Гбит/с или Wi-Fi стандарта 802.11n. Многие организации не приобрели инструменты для таких технологий, потому что считают, что существенное увеличение ресурсов поможет решить любые проблемы.
- Беспроводные устройства — инженеру нужен способ для выявления и мониторинга устройств Wi-Fi, в том числе личных устройств пользователей, а также для обнаружения помех, вызванных оборудованием Wi-Fi, устройствами Bluetooth, беспроводными телефонами, микроволновыми печами и т. д. с помощью спектрального анализа.
- Проблемы за пределами сети: инженеру необходимо выявить и устранить их, а также предоставить вспомогательные данные другим ИТ-группам или внешним поставщикам услуг для дальнейшего анализа и быстрого устранения.
Новый подход к решению проблем
Необходимо комплексное решение для анализа производительности сети и приложений, которое захватывает все данные в сети и выполняет интеллектуальный анализ, чтобы инженеры могли быстрее изолировать причину проблемы или определить, находится ли она за пределами сети. Оно должно собирать, объединять, коррелировать и передавать всю информацию, включая потоки, данные SNMP и информацию, собранную от других устройств со степенью детализации до одной миллисекунды. Данные должны отображаться на одной настраиваемой информационной панели, где можно применять рабочие процессы для быстрой изоляции основной причины проблемы. Если устранить догадки и позволить пользователю следовать логическому процессу для определения и устранения неполадок, можно снизить среднее время диагностики и повысить эффективность сетевых инженеров.
Решение для анализа производительности сети и приложений реализует все этапы процесса устранения неполадок и обеспечивает видимость, необходимую для оптимизации сети.
ШАГ ПЕРВЫЙ: МОНИТОРИНГ И ОПОВЕЩЕНИЕ
Первый необходимый компонент при анализе и устранении проблем сети — система, которая своевременно оповещает о возникновении проблемы. В худшем случае это звонок от пользователя, при этом инженер уже оказывается в невыгодном положении. Многие инструменты управления сетью необходимо настроить вручную для каждой сети, чтобы система обнаруживала все устройства в каждом широковещательном домене. Однако при использовании непрерывно работающего решения анализа производительности сети и приложений автоматическое обнаружение и удобные рабочие процессы позволяют легко понять, что и с чем связано. Это существенно уменьшает время, необходимое для настройки и мониторинга.
Данные производительности непрерывно собираются и сохраняются в базе данных и отображаются на панели мониторинга производительности, которую пользователь может настроить с учетом собственных потребностей. Производительность отслеживается на основе базовых показателей, заданных пользователем (например, соглашения об уровне обслуживания), и любые тревожные события немедленно отображаются в системе. Затем пользователь может изучить проблемы с различной степенью детализации на стадии анализа.
Системы мониторинга производительности сети и приложений также могут быть интегрированы с существующими системами управления сетями, такими как HP OpenView или Tivoli Netcool, и могут передавать данные и оповещения решениям для управления службами и панелям мониторинга.
ШАГ ВТОРОЙ: ИССЛЕДОВАНИЕ
Теперь сетевому инженеру необходимо изучить масштаб проблемы. Для проведения быстрого и точного исследования решение должно собирать все соответствующие сведения, например данные SNMP, потоки, пакеты, время реагирования конечных пользователей и т. д., и сохранять их для последующего анализа. Решение мониторинга производительности сети и приложений также позволяет в реальном времени определять маршрут от клиента до службы или приложения, значительно уменьшая время для анализа. После этого можно выявить канал между двумя устройствами для мониторинга проблем во внутренних и внешних сетях, а также в устройствах в них. Результаты отображаются в графическом формате, что позволяет упростить интерпретацию и ускорить анализ основных причин.
Для оптимальной эффективности система должна поддерживать интерфейсы со скоростями 1 Гбит/с и 10 Гбит/с, а также захват данных на скорости канала. Некоторые решения могут проследить маршрут в сети от клиента до сервера, обнаруживая устройства 2 и 3 уровня и предоставляя детализированные сведения для определения источника проблемы.
Если неполадки вызваны клиентом или группой клиентов, инженер должен выполнить тест производительности или реагирования приложений, чтобы определить, вызвана ли проблема проблемой проводной или беспроводной сетью. Предоставляя инструменты для анализа проводной и беспроводной сети, интегрированные в единый пользовательский интерфейс, система мониторинга сети и приложений позволяет с помощью одного теста выявить источник проблемы.
ШАГ ТРЕТИЙ: ИЗОЛЯЦИЯ
На этом этапе проблема изолирована в одном сегменте сети, коммутаторе, маршрутизаторе, сервере или приложении, при этом определены маршрут и все затронутые устройства и порты. Теперь необходимо проанализировать маршрут, чтобы получить статистику по трафику для каждого канала и выяснить, вызваны ли неполадки неисправным устройством, кабелем, помехами или перегрузкой трафика.
Одно из величайших преимуществ протокола SNMP — это возможность изолировать неисправный участок. Используя SNMP, можно опросить каждую точку подключения, чтобы определить, вызвано ли замедление узким местом при передаче трафика. Это просто, если устройства в маршруте управляемые, а у инженера есть пароли или строки доступа для опроса устройств. В противном случае потребуется подключить инструмент к каждому каналу без нарушения целостности сети для просмотра пакетов и статистики трафика. Для этого может потребоваться очень много времени, если каналов много и они находятся в масштабной географической области, и множество инструментов на различных объектах.
Автоматизированная проверка состояния сетевой инфраструктуры с помощью инструмента мониторинга производительности сети и приложений позволяет контролировать все поддерживаемые SNMP-устройства, анализируя потоки приложений с потерей пакетов или высокой загруженностью, регулярно опрашивая базы MIB SNMP в маршрутизаторах. Процесс будет простым и быстрым даже для десятков и сотен коммутаторов в сети.
Некоторые проблемы проявляются только в конкретной точке. Для их обнаружения требуется портативное устройство с широкими возможностями тестирования и нужным интерфейсом для подключения к проблемной точке, будь то клиент или канал 10 Гбит/с в центре обработки данных. Сейчас многие работают удаленно, поэтому инструмент, который обеспечит такую видимость, просто незаменим, а с ростом числа личных устройств на работе он станет еще более важным компонентом.
Портативный прибор можно отправить на удаленную площадку, чтобы посмотреть, что конкретно происходит с неуправляемым оборудованием в сети. При этом отправлять на место инженера совершенно необязательно. В идеале он должен анализировать маршрут, оценивать состояние инфраструктуры и потоков приложений, анализировать производительность WLAN, возможности роуминга, а также любые помехи от внешних устройств.
Если нет перегруженных каналов или ошибок кадров, проблема не в сети. Но подтвердить это можно, только если инженер проанализировал каналы в течение соответствующего периода времени, а проблема по-прежнему существует. Для этого система мониторинга производительности сети и приложений должна записывать данные в течение длительного времени.
ШАГ ЧЕТВЕРТЫЙ: АНАЛИЗ ПРИЧИН ВОЗНИКНОВЕНИЯ ПРОБЛЕМЫ И ЕЕ УСТРАНЕНИЕ
На данном этапе инженер подтверждает причину проблемы, разрабатывает, применяет и проверяет решение. Если проблема не заключается в сети, скорости реагирования сервера или перегрузки ресурсов, требуется получить более подробную информацию за счет захвата и анализа пакетов. Сначала важно изолировать канал или проблему между сервером, сетью и приложением, так как для анализа пакетов требуется очень много времени и богатый опыт.
Чтобы быстрее добраться до основной причины лучше всего начинать с уровня приложений. Например, если сетевой тракт в порядке, но время отклика — нет, значит проблема может заключаться в виртуализированном сервере, приложении, которое работает на нескольких уровнях или в ошибке приложения.
Один из вариантов — использовать анализатор пакетов, который показывает данные на уровне приложений и многоступенчатые схемы пакетов. Протяженные или зеркальные ответвленные соединения легко настроить, но они могут терять пакеты при интенсивном трафике, и для них не отображаются ошибки 1 уровня, так как они блокируются коммутатором 2 уровня. Пассивные разветвители являются лучшими, но при их подключении разрывается соединение, а пользователи лишаются доступа к соответствующим службам. Если производительность падает, это обычно не вызывает проблем, но может повлиять на тех, кто использует этот канал для подключения к другим службам.
Лучшим решением будет сеть с уже готовыми ответвлениями трафика, размещенными перед стойками серверов, центрами обработки данных, маршрутизаторами внешних каналов и в ядре сети. Это позволяет захватывать пакеты без нарушения работы сети. Если это невозможно инженеру может потребоваться использовать зеркалирование диапазонов или портов, принимая во внимание сопутствующие проблемы и неточности.
Решение для мониторинга производительности сети и приложений предоставляет автоматизированный метод просеивания захваченных пакетов для поиска проблемных. Оно использует ориентированный на приложения подход с пользовательским интерфейсом, в котором отображается каждый поток данных с визуальным индикатором проблем. Инженер может просто щелкнуть его, чтобы просмотреть подробные сведения и узнать, в каких пакетах возникли проблемы. Для более точного анализа можно захватить пакеты в нескольких точках инфраструктуры, чтобы определить, где возникает проблема. Для этого требуется возможность для многосегментного анализа, одновременного сбора данных в нескольких точках и объединения результатов для получения полной картины.
Эффективный анализ основных причин может осуществляться в центре обработки данных или на удаленных площадках, чтобы узнать, связаны ли проблемы с серверами или приложениями. Некоторые инструменты могут извлечь данные об управлении из физических или виртуальных серверов, чтобы установить причины с производительностью или дефицитом ресурсов.
Собирая и анализируя детализированные исторические данные, система мониторинга производительности сети и приложений также позволяет инженеру вернуться назад во времени для изучения симптомов, которые проявились, когда проблема возникла впервые, чтобы выявлять и устранять кратковременные проблемы.
Оптимизация сети
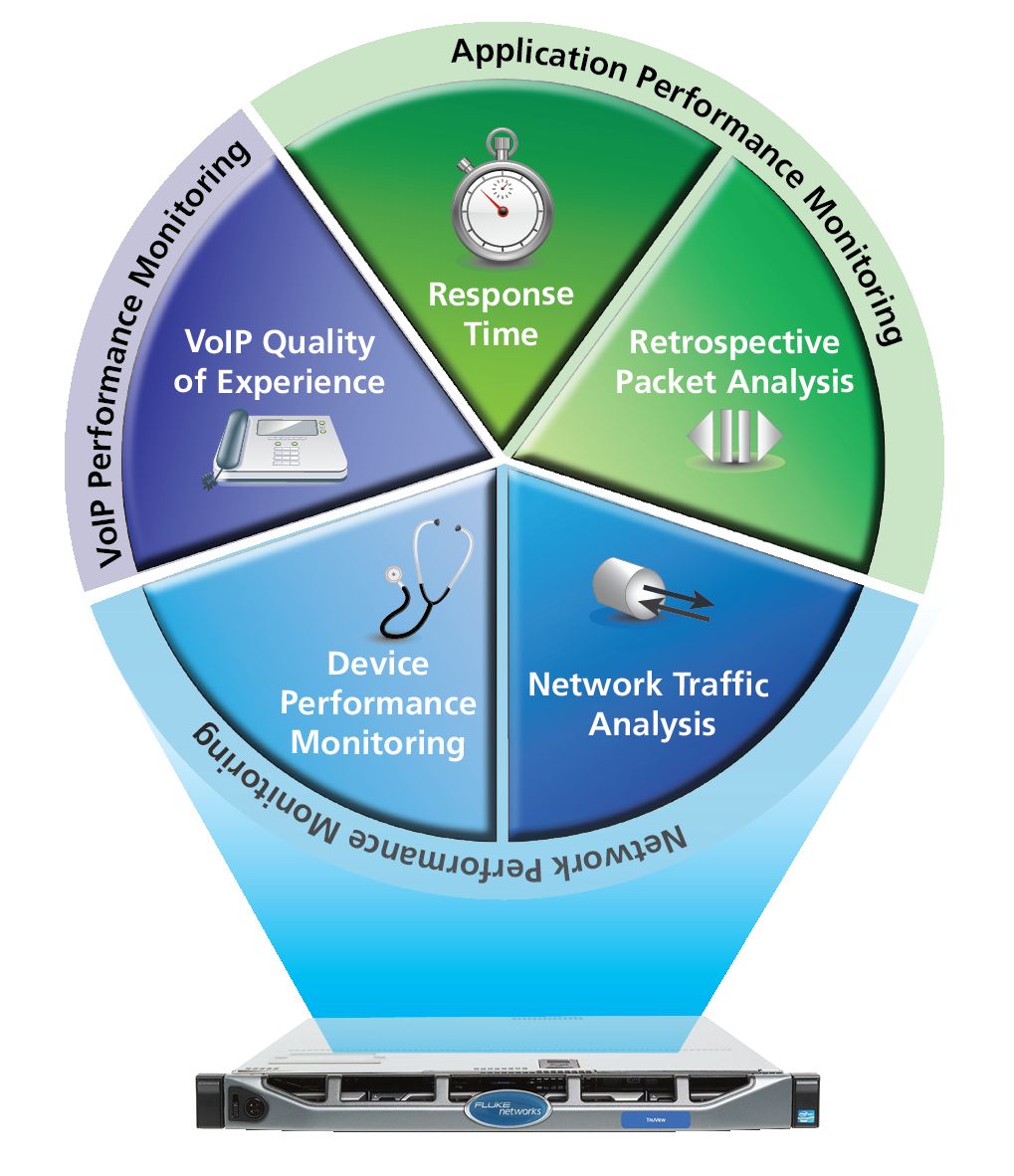
Решение для мониторинга производительности сети и приложений предоставляет инженерам сведения, необходимые для документирования и аудита состояния корпоративной сети. Оно также позволяет им определить замедления в работе приложений и определить, в каких точках работа приложений или серверов замедлена, чтобы внести необходимые изменения. Полученная информация может использоваться для определения приоритетности проектов, таких как обновление серверов и обоснования необходимых изменений. Она также может помочь при установке нового оборудования и приложений, так как инженеры смогут проверить, какие решения сработали, и убедиться, что они не повлияли на производительность других компонентов. Данные также могут подтвердить влияние изменений сети, таких как виртуализация, оптимизация WAN или консолидация центра обработки данных.
Источник: компания NETSCOUT
Перейти в раздел анализаторы трафика, производительности сети и приложений
См. также: